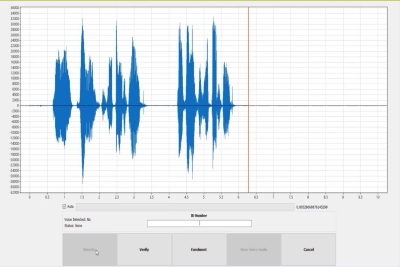
Voice Recognition System
The voice identification technology is designed for biometric system developers and integrators. The text-dependent speaker recognition algorithm assures system security by checking both voice and phrase authenticity. Voiceprint templates can be matched in 1-to-1 (verification) and 1-to-many (identification) modes.
a software development of stand-alone and Web-based solutions on Microsoft Windows, Linux, macOS, iOS and Android platforms.
* Text-dependent algorithm.
* phrase for enrollment and verification.
* Two-factor authentication with a passphrase.
* Text-independent algorithm.
* Automatic voice activity detection.
* Liveness detection.
* Identification capability.
* Multiple samples of the same phrase.
* Fused matching.
The voiceprint-matching algorithm can be configured to work in a scenario where each user records a unique phrase (such as passphrase or an answer to a "secret question" that is known only by the person being enrolled). Later a person is recognized by his or her own specific phrase with a high degree of accuracy. The overall system security increases as both voice authenticity and passphrase are checked.

The phrase-independent speaker recognition uses different phrases for user enrollment and recognition. This method is more convenient, as it does not require each user to remember the passphrase. It may be combined with the text-dependent algorithm to perform faster text-independent search with further phrase verification using the more reliable text-dependent algorithm.

It's able to detect when users start and finish speaking.
The functions can be used in 1-to-1 matching (verification) and 1-to-many (identification) modes.
FEATURES AND CAPABILITIES
Text-dependent algorithm:
The text-dependent speaker recognition is based on saying the same phrase for enrollment and verification. The System algorithm determines if a voice sample matches the template that was extracted from a specific phrase. During enrollment, one or more phrases are requested from the person being enrolled. Later that person may be asked to pronounce a specific phrase for verification. This method assures protection against the use of a covertly recorded random phrase from that person.
Two-factor authentication with a passphrase:
The System voiceprint-matching algorithm can be configured to work in a scenario where each user records a unique phrase (such as passphrase or an answer to a "secret question" that is known only by the person being enrolled). Later a person is recognized by his or her own specific phrase with a high degree of accuracy. The overall system security increases as both voice authenticity and passphrase are checked.
Text-independent algorithm:
The phrase-independent speaker recognition uses different phrases for user enrollment and recognition. This method is more convenient, as it does not require each user to remember the passphrase. It may be combined with the text-dependent algorithm to perform faster text-independent search with further phrase verification using the more reliable text-dependent algorithm.
Automatic voice activity detection:
It's able to detect when users start and finish speaking
Liveness detection:
A system may request each user to enroll a set of unique phrases. Later the user will be requested to say a specific phrase from the enrolled set. This way the system can ensure that a live person is being verified (as opposed to an impostor who uses a voice recording).
Identification capability:
The System functions can be used in 1-to-1 matching (verification) and 1-to-many (identification) modes.
Multiple samples of the same phrase:
A template may store several voice records with the same phrase to improve recognition reliability. Certain natural voice variations (i.e. hoarse voice) or environment changes (i.e. office and outdoors) can be stored in the same template.
Fused matching:
A system may ask users to pronounce several specific phrases during speaker verification or identification and match each audio sample against records in the database. The System algorithm can fuse the matching results for each phrase together to improve matching reliability.